Добрый день, группа 312!
Вторая и третья задачи
Параллельное программирование с общей памятью
Библиотека pthreads
Средства синхронизации библиотеки pthreads
Вторая и третья задачи
Если вы не получили вторую задачу — подойдите после презентации.
Третья задача — параллельная реализация алгоритма решения линейной системы (решения матрицы) с использованием библиотеки pthreads. Нужно реализовать параллельную версию вашего метода из первой задачи. При этом программа должна принимать в качестве одного из агрументов количество потоков.
При увеличении потоков на достаточно больших матрицах (2000x2000, 4000x4000) программа должна ускоряться, на 2 потоках — хотя бы в 1.6 раза, на 4 потоках — в 3 раза. На одном потоке программа не должна быть существенно медленнее, чем однопоточная реализация
Литература
- К.Ю. Богачёв. Основы параллельного программирования.
- Мобильное программирование приложений реального времени, Лекции 1,2
Небольшие примеры, введения, презентации:
Программы исполняются последовательно
Программы на языке C транслируются в машинный код — последовательность простых команд для процессора:
void foo(int x) {
if (x == 0) {
printf("testing\n");
}
}.globl _foo
_foo: ## @foo
testl %edi, %edi
je LBB0_2
retq
LBB0_2:
leaq L_str(%rip), %rdi
jmp _puts
L_str: ## @str
.asciz "testing"Современные процессоры имеют несколько ядер
— т.е. они могут выполнять несколько «потоков команд» (программ) одновременно.
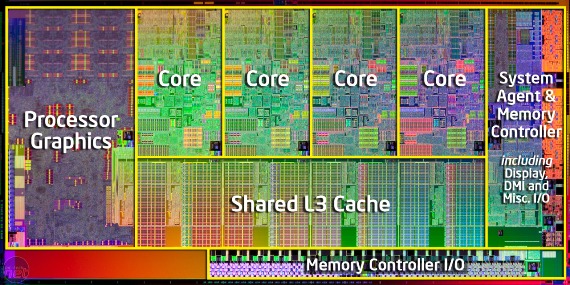
Потоки (threads)
— способ запуска нескольких потоков исполнения параллельно, с разделяемой памятью и ресурсами.
Т.е. можно обмениваться указателями, выполнять одновременное чтение и запись, и так далее. Если просто запустить несколько копий программы, у каждой копии будет своё пространство памяти и они не смогут взаимодействовать.
Для использования потоков нужно дать специальную команду «создать поток» и указать, какие команды этот поток должен исполнять.
В Linux (и на Mac) потоки реализованы согласно спецификации POSIX Threads.
В командную строку при компиляции добавить: -pthreads или -lpthreads
В исходный код:
#include <pthread.h>Потоки и общая память
Когда программа использует потоки, можно считать, что в этой программе одновременно выполняется несколько функций (или несколько копий одной функции). При этом в общем случае про взаимную последовательность выполнения команд функций (какой поток раньше считает элемент матрицы) ничего неизвестно.
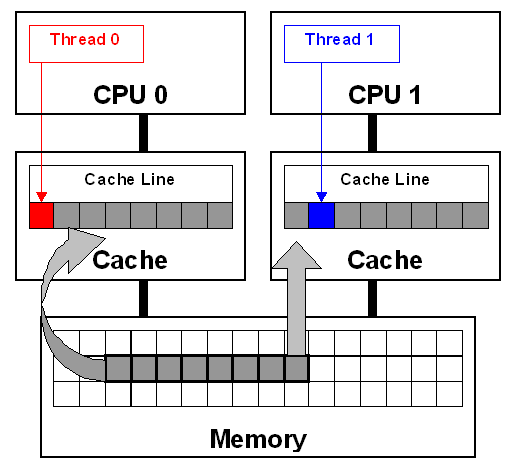
Создание потока
pthread_t thread;
int pthread_create(pthread_t *thread,
const pthread_attr_t *attr,
void *(*start_routine)(void*),
void *arg);
void pthread_exit(void *retval);
int pthread_join(pthread_t thread, void **retval);
Создание потока
int pthread_create(pthread_t *thread,
const pthread_attr_t *attr,
void *(*start_routine)(void*),
void *arg);thread- (выходной аргумент) — идентификатор потока
attr- атрибуты, можно оставить
NULL start_routine- указатель на функцию, главную для потока
void *child_thread_func(void* arg) arg- указатель на аргумент, передаваемый главной функции
pthread_exit вызывать необязательно, можно просто возвращаьт значение через return
pthread_join ожидает завершения потока-аргумента и возвращает ненулевое значение, если поток вернул результат, который будет записан по адресу retval
Мьютэксы (mutex)
Поток, в котором была первой вызвана функция pthread_mutex_lock, захватывает мьютэкс. Выполнение остальных потоков при вызове pthread_mutex_lock блокируется до вызова pthread_mutex_unlock потоком, захватившим мьютэкс.
pthread_mutex_t mutex;
int pthread_mutex_init(pthread_mutex_t *mutex,
const pthread_mutexattr_t *attr);
int pthread_mutex_destroy(pthread_mutex_t *mutex);attr может быть NULL
int pthread_mutex_lock(pthread_mutex_t *mutex);
int pthread_mutex_unlock(pthread_mutex_t *mutex);Мьютэксы

(Li) lock(mi) (Ui) unlock(mi)
Взаимная блокировка (deadlock)

При использовании более чем одного мьютэкса возможна ситуация, когда потоки блокируют друг друга — синий поток ожидает мьютэкс 1 для того, чтобы потом разблокировать мьютэкс 2, который требуется красному потоку для разблокировки мьютэкса 1.
Условные переменные (condvar)
С помощью условных переменных потоки могут передавать сигналы о готовности данных и т.п. Потоки, вызывающие pthread_cond_wait блокируются до момента, когда какой-либо активный поток вызовет pthread_cond_signal (разблокирует один поток) или pthread_cond_broadcast (разблокирует все ожидающие потоки)
int pthread_cond_init(pthread_cond_t *cond,
const pthread_condattr_t *attr);
int pthread_cond_destroy(pthread_cond_t *cond);int pthread_cond_wait(pthread_cond_t *cond,
pthread_mutex_t *mutex);
int pthread_cond_signal(pthread_cond_t *cond);
int pthread_cond_broadcast(pthread_cond_t *cond);mutex — один и тот же для всех операций с фиксированной условной переменной
Условные переменные (condvar)

(W) — wait, (S) — signal, (B) — broadcast
Барьеры (barrier)
Барьеры определяют точки синхронизации, в которых потоки ожидают, пока до данной точки дойдёт заданное количество потоков.
int pthread_barrier_init(pthread_barrier_t *barrier,
const pthread_barrierattr_t *attr, unsigned count);
int pthread_barrier_destroy(pthread_barrier_t *barrier);
int pthread_barrier_wait(pthread_barrier_t *barrier);count — количество потоков
Барьеры — наиболее простой примитив синхронизации, я советую использовать в задачах именно его.
Барьеры (barrier)

(A) wait (barrier count = 2)
(B) wait (barrier count = 3)
Схема распараллеливания задач
Количество потоков P передаётся как аргумент командной строки.
В main создаётся P потоков с одной функцией, в которую передаются:
- общие для всех потоков данные: размер матрицы, указатель на матрицу и обратную матрицу (или правую часть), указатели на дополнительную общую память
- данные, специфичные для каждого потока: номер потока, указатели на собственную память.
Матрица распределяется по потокам-«владельцам» циклически, по строкам или по столбцам (1-я строка — 1-й поток, …, P-я строка — P-й поток; P+1-я строка — 1-й поток, …). Это делается для того, чтобы при уменьшении части матрицы, с которой работает метод, потоки не начинали простаивать. Лучше и распределять по потокам, и хранить элементы матрицы по столбцам.
Псевдокод main
P, n, ... = получить аргументы командной строки
matrix, inverse_matrix, tmp_common, tmp_specific[P] = выделить память
matrix, inverse_matrix = считать входные данные
threads = new pthread_t[P]
thread_args = new thread_args[P]
pthread_barrier_t barrier;
pthread_barrier_init(&barrier, NULL, P)
for p=[0…P):
thread_args[p] ⟵ n, P, matrix, inverse_matrix, tmp_common, barrier
thread_args[p] ⟵ tmp_specific[p], p
pthread_create(threads+p, NULL, Func, thread_args+p)
for i=[0, P):
pthread_join(threads[p], NULL);
очищаем память, уничтожаем потоки, барьер и т.п.Псевдокод func
void* func(void* args) {
thread_args A = (thread_args) args;
n, P, matrix, inverse_matrix, tmp_common, barrier, tmp_specific, p ⟵ A
for i=[0…n): - цикл по диагональным элементам
j0 = i
if i%P == p: — текущий поток — владелец текущего столбца
подготовить в tmp_common данные для обнуления i-го столбца
обнулить i-й столбец, j0 = i+1
pthread_barrier_wait(barrier)
for j=[j0…n):
применить преобразование из tmp_common к своим столбцам матрицы
for j=[0…n): — если обращение матрицы, иначе - без цикла
применить преобразование из tmp_common к правой части
pthread_barrier_wait(barrier) — можно убрать, если чередовать tmp_common
по чётным-нечётным шагам
for i=[0…n):
обратный ход метода Гаусса
pthread_barrier_wait(barrier)
return NULL;
}Замечания
- Если многопоточная программа, в которой не используются циклы
whileне завершается, скорее всего, имеет место блокировка (deadlock, не все потоки доходят до барьера и т.п.) - Чем больше синхронизаций, тем хуже ускоряется программа.
- Если программа при нескольких запусках на нескольких потоках возвращает недетерминированный результат (при каждом запуске разный с одними и теми же входными данными), то проблема в несинхронизированном чтении.
- Внимание: самостоятельно нужно сделать обработку ошибок, чтобы, если один поток решил, что матрица вырожденная, другие тоже об этом узнавали и заканчивали выполнение. Main тоже нужно как-то уведомить — через общую память в tmp_common, например.
- Желательно распараллелить и умножение матрицы для вычисления невязки, чтобы можно было, например, дождаться результатов на 4000x4000